Can GPT Perform Value Investing?
David Katz, Bastian Silva, and Mahuna Akplogan - 2nd October 2023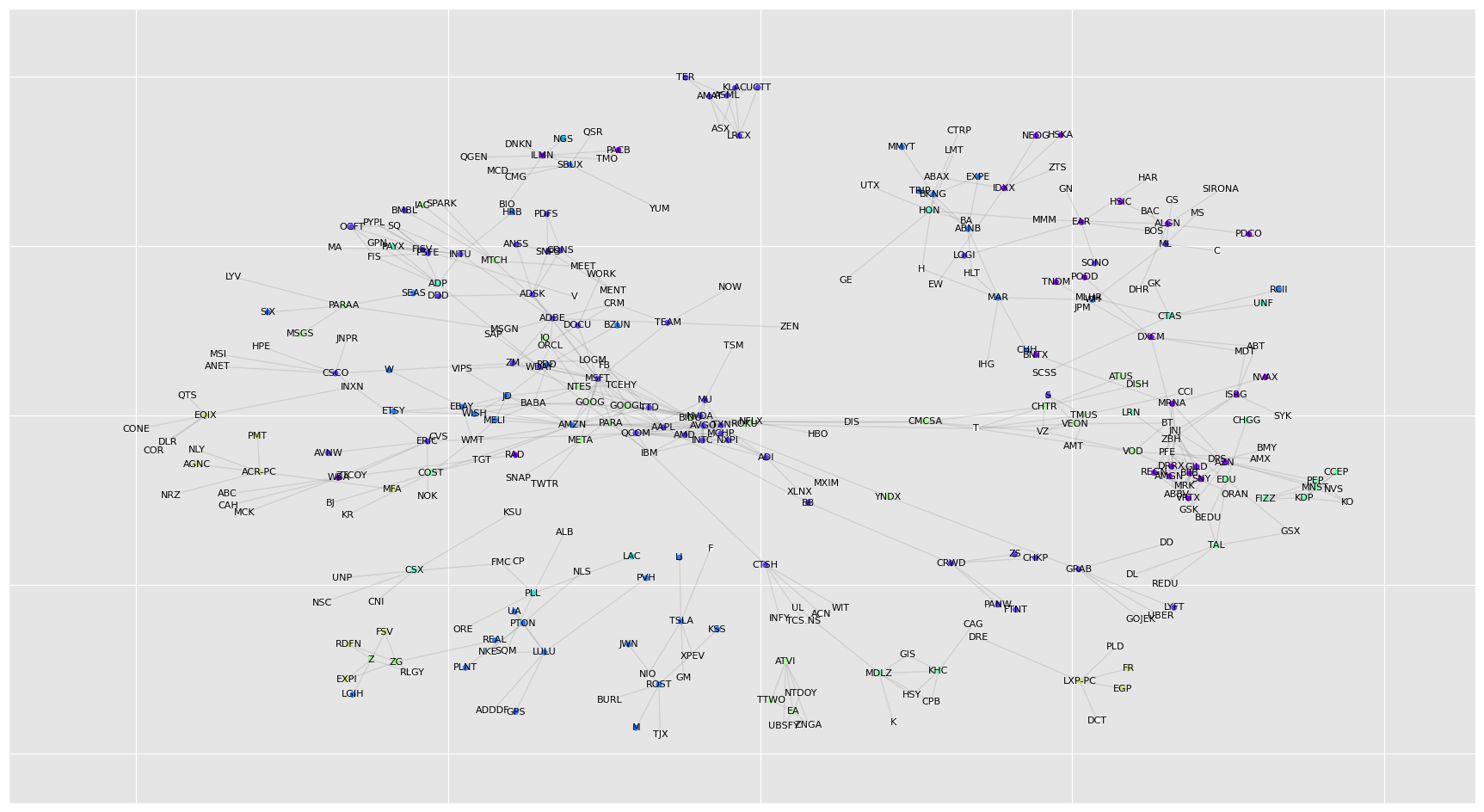
We built a system to conduct intrinsic value analysis on the stock market using GPT and analyzed how performant the system was in differentiating overvalued companies from undervalued ones. We found moderate evidence that indicated large language models can have an influential role in the fundamental analysis of corporate stock data.
In this study we examine the potential that GPT 4 has in predicting the degree to which a company is overvalued or undervalued in the stock market by prompting it to systematically analyze a company and its competitors' data.
In the paper Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models, published in 2023, showed the ability large language models have in producing profitable portfolios by using GPT to predict the impact a piece of news will have on a company’s stock price and then positioning a trade in the direction of predicted movement. Given that GPT can handle nuances in human language, it is expected that it will produce high quality “sentiment” predictions that are tailored to the context and the impact that it will have on a company.
Given the success in applying enhanced sentiment analysis to stock news, our team started to think about what experiment could we conduct to learn more about the potential LLMs have as part of a trading system with a larger time horizon such as quarterly.
To proceed with our experimentation we decided on a method to evaluate the ability GPT, and similar language models, have in predicting price action based on an analysis of a company’s and its competitors' financials with a focus on the long term (compared to daily trading models)
In our experiment we developed a systematic way of prompting the language model that instructed it to perform a valuation of the company with respect to its nearest competitors. The prompt contains a snapshot of the company (and its competitors) financials based on the data the companies provide in the SEC filings along with a few price indicators.
In order to ensure that the analysis is free of out-of-sample biases we only analyzed a limited number of financial quarters that are all after the GPT4 training cutoff date of September 2021. Unfortunately 2022 was one of the worst years for the stock market in recent years and hence on average most of the stocks exhibited negative returns.
There are many factors that impact the price change of a company’s stock, they are fundamentally related to the expected growth and earnings potential of a company. One school of thought in financial economics is the view that due to imperfections in human biases, some companies may be trading above their actual value, or below their actual value. A prominent stock investing technique popularized by experts such as Benjamin Graham and Warren Buffet is to determine, through analysis, which companies exhibit levels of valuation that are not aligned with their true valuation. Advocates of this theory promote the idea of the intrinsic value of a company, a figure that represents the true value of a company. The market value of a company is not necessarily equal to its intrinsic value, and hence when the possibility of a difference between these two figures exists, it is possible to exploit this asymmetry to generate outstanding market returns.
While there is clear evidence to suggest that capital markets are very efficient in reacting to information, they are not perfect and some phenomena cause them to allow for such arbitrage opportunities. Some of these phenomena are information asymmetry, irrational herd behavior, overreacting to news, and different interpretation of data to different groups of people.
Value investing is rooted in the idea that markets correct themselves in the long run, but at shorter time horizons they can produce profitable opportunities for investors.
Our engineering challenges surrounded the mechanism for building a prompt that includes a snapshot of a company’s financials at a specific moment in time and use this information to determine if the company is undervalued, neutrally valued, or overvalued. Following the assumption that markets correct valuation in the limit we use the signal generated by GPT to position trades that move in the same direction of our signal.
Our method consists in three phases: the first is to create a set of companies that are comparable to each other, the second is to systematically query GPT4 to produce a classification of the value of that a company is exhibiting, and third is to analyze the performance predictions against stock price movements.
In order to construct a network of comparable companies we tried a different approach but found that querying GPT was the best approach. For every stock that we were analyzing we querying GPT to produce the tickers of its main competitors. Once this process was completed we used the louvain community detection algorithm to construct communities centered around individual stocks.
Once we have created our network and communities our next step is to produce a financial snapshot of every company in our network along with a snapshot of its competitors' financials at different points in time. We created a snapshot at the start of each financial quarter in 2022. This “snapshot” provides 7 key variables that analysts commonly use to compare the performance of stocks. These variables are: total assets, total liabilities, net income TTM, net cashflow TTM, total revenue TTM, adjusted close, and shares outstanding.
With our snapshots for every company in our study we proceeded to pass the snapshot as a context in a larger prompt that was engineered to produce a classification for the intrinsic value of a company. Each company produced 4 classifications throughout the year.
The following is a completion from GPT for a company classified as “undervalued”:
The third stage in our analysis was to correlate the predicted intrinsic value with actual stock price movements. With our signal produced at the start of each quarter, we analyzed the price movement of the stocks with different time horizons and found the strongest correlation between signal and response at a horizon of 3 months.
Due to the random nature of GPT we ran our second step of generating the analysis of each company three times and averaged out the results.
In addition to our GPT powered analysis method we compared it to a baseline method of comparing return on assets and price to earning ratios and found that our baseline signal had an average correlation of only 5% as opposed to 16% to the signals produced by the GPT powered system.
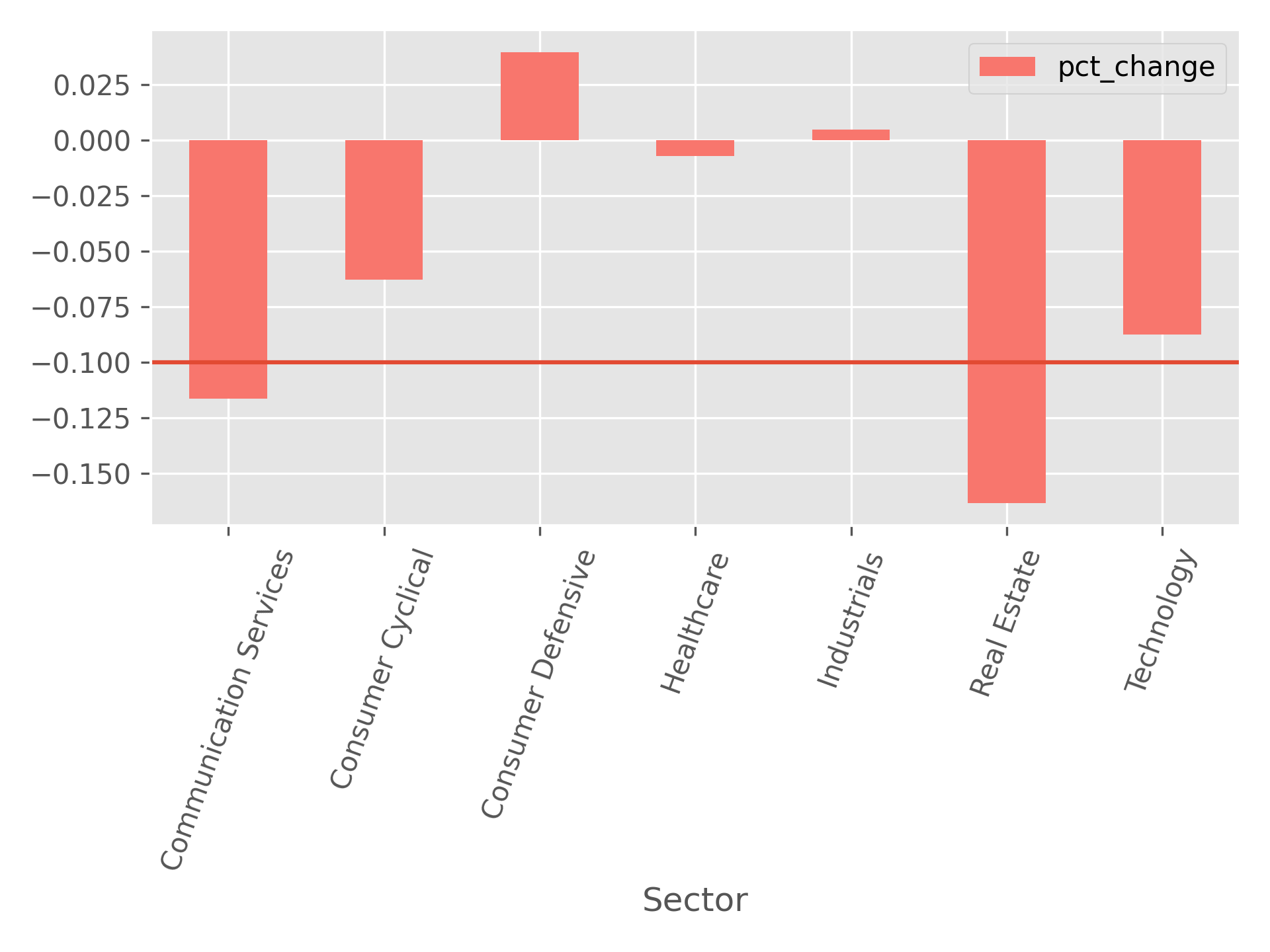
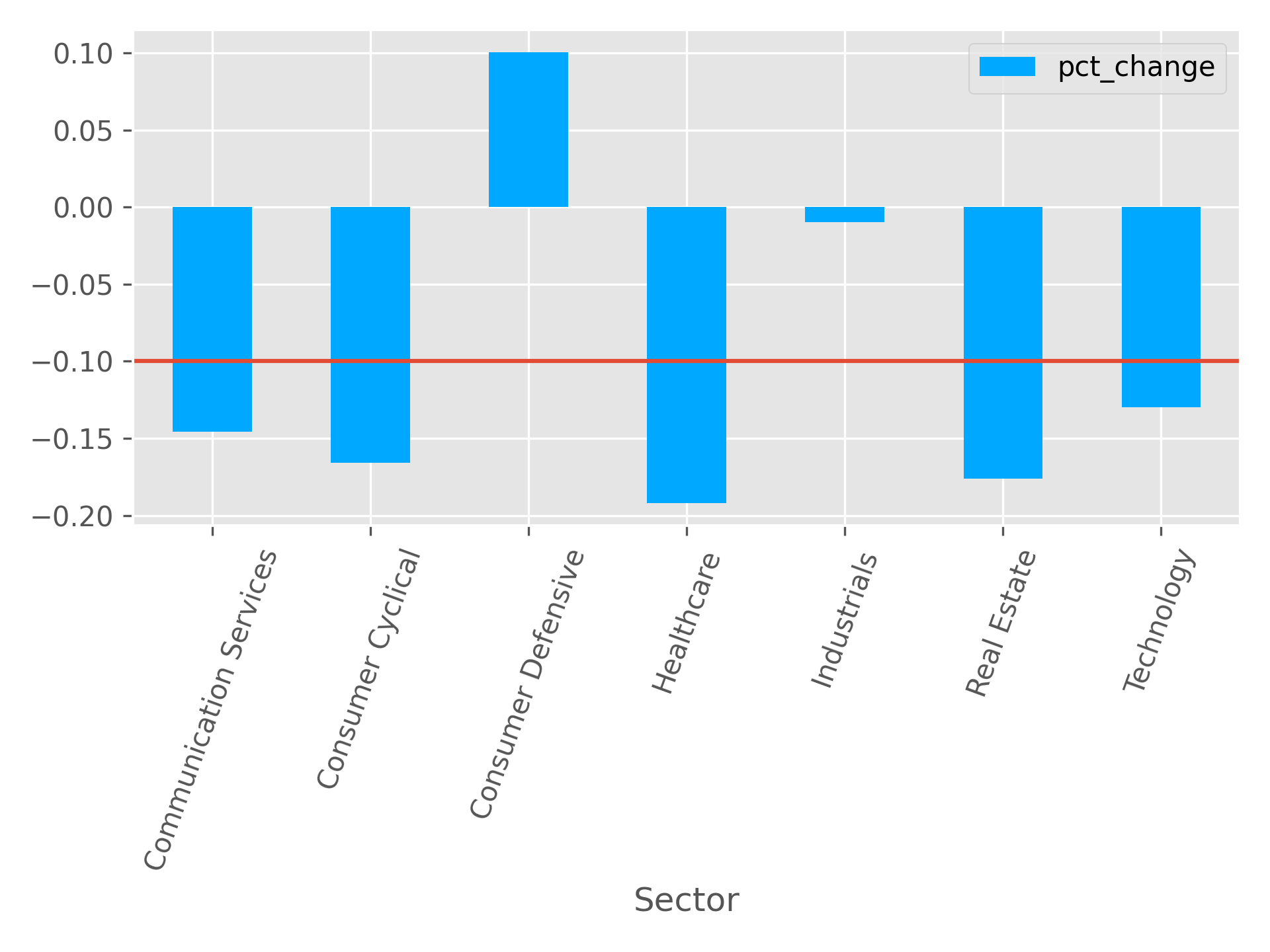
The group of stocks that were identified as undervalued exhibited on average -6% returns. The group of overvalued stocks exhibited average returns of -15% returns.
The standard deviation of the returns for the group identified as undervalued was 16% and 29% for the overvalued stocks.
We are eager to dive deeper into this technique and understand how large language models can be integrated into complex decisions and tasks surrounding financial markets. Further directions of research can be in automating the prompt optimization by using the objective of predicting price movements, using other language models, and providing more variables of data to analyze.
Pro’s to our methodology
Systematic and correct passing of context to language model to produce a prediction of value, injection of context is “template based”.
Showed there is potential in using language models to analyze a company beyond the psychological impact of a news segment on the market, such as Lopez-Lira et Al.
Stocks that were predicted to be undervalued clearly outperformed the group of stocks predicted to be overvalued, indicating an ability to differentiate
Our system does not conduct end-to-end optimization, potentially we could apply hyper-parameter search style algorithms to find the combination of parameters that maximize the objective of predicting price action within a three month horizon.
Cons to our methodology
2022 was an overall bad year and a limited horizon of analysis, these types of stock benchmarks should be conducted over multiple years.
Models can tend to fixate on a subset of variables and not take a holistic approach.
Model is limited by how well we prompt it and is highly stochastic
Model is limited by the data we decide to provide it and how models actually react to different prompts.
Conclusions
In our study we developed a systematic approach to generate stock value predictions by systematically injecting financials into a completion process. Given that we tested our results on a relatively limited amount of features and given the clear distinction between the undervalued and overvalued classes we believe that company valuation is a task that could be more effectively solved by language models with further research and development.
Figure 1 - Network of large cap stocks
Other
Real Estate
Communication Services
Consumer Defensive
Industrials
Basic Materials
Energy
Consumer Cyclical
Technology
Healthcare
Figure 2 - Stock Returns by Classification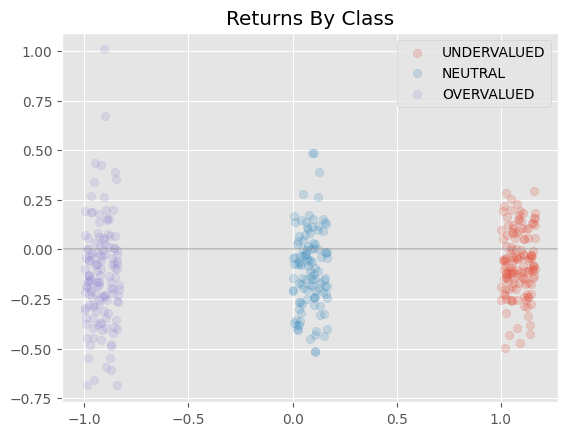
Figure 3 - Returns by Sector: Undervalued vs overvalued